Today, a short blog post to share my excitement about a git feature that I recently discovered : git-worktree. I’d like to tank the @Primagen for sharing it!
NB: This article suppose that your are familiar with git and will not explain terms such as checkout, push, pull… Also this is not a tutorial on how to use git-worktree.
What is git-worktree?
I like to think of git-worktree as synchronised local git repositories.
The important word here (as you might guess) is synchronised.
It means that you can have different directories in your file system that are pointing to different nodes of the same git history as follow:
.
├── dir 1 -> branch `dev` commit ae12kd8
├── dir 2 -> branch `main` commit ae12kd8
└── dir 3 -> branch `feat/foo` commit bfec521
Magic? At least for my use case!
To better understand that magic, I let you check the documentation: git-worktree
Why are they suited to AI research code?
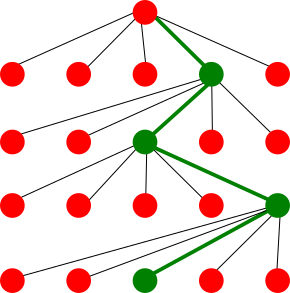
The aims of a software and research code are different. A software aims to be used by someone else than its developer, and therefore needs to work out of the box, and be intuitive. A research code aims to prove a point, and his rarely used by other people than its developer; in industry terms it is close to a proof of concept. It is generally developed through tries and errors as illustrated in the fictive git tree below. Therefore, quick implementation of ideas and quick experimentation is essential to the development of research code. In practice, that translates by the creation of many feature branches which might be abandoned as quickly as they were created.
 In addition, AI have an extra particularity: a (very) long execution time.
Many side effects might happens during the execution of your code (calling subprocesses from different files, moving files around etc.).
Then,
In addition, AI have an extra particularity: a (very) long execution time.
Many side effects might happens during the execution of your code (calling subprocesses from different files, moving files around etc.).
Then, stashing and checking out your repository during the execution of the code is a risky business…
Risky business that might kill hours of computation.
Not really good for the planet, or your sanity!
Using git-worktree allows you to work on as many features as you want without disturbing the structure of the directory of the code your running.
Great, right?
(Am I the only one excited about this?)
Side note about of AI script running time: when I administrated the cluster of GPU of my lab, we fixed the time-out of the longest queue to 1 months. (And we still had complains that it was too short…).
How do I use it
Let’s say that the training of my latest AI project does not work (as often…). I have a meeting with my supervisor and we come up with n new idea to test: (idea-1, …, idea-n). From those ideas only a few (at best) will make it to the code that ends up in the research paper.
In my repository, this will translate by the creation of n feature branches (feat/idea-1, …, feat/idea-n).
And this is where git-worktree enters the scene
[path]/dev$ git worktree add -b feat/idea-i ../idea-i
[path]/dev$ cd ../idea-i
[path]/idea-i$ git push -u origin feat/idea-i
After I did that, for all feature branches I have a separate directory:
.
├── results
├── dev
└── idea-1
.
.
.
└── idea-n
and I can nicely work on each of my features separately.
Once a feature is ready (which can be very quick) I can validate or invalidate the idea by running the training of the AI (e.g. PYTHONPATH=idea-1 python run.py).
The unsuccessful git-worktree are removed, and I can merge or cherry-pick some commits from the successful ones.
Conclusion
git-worktree simplified the administration of my research projects.
It also allowed me to fearlessly try all my (or my supervisor’s) most exotic ideas.
Possible improvement(s)
- So far, the creation of feature branches is quite manual. I could wrap it in a shell script
- It would be nice to integrate this better in my vim workflow. The @Primagen (him again) released git-worktree.nvim but I did not try it yet.